


Overview
(UPDATED -5/22/2019) In the coming months the SUM Global team will be creating a series of posts that will build out a Kubernetes cluster on 6 Raspberry Pi 3s (RPi). It will utilize persistent volumes and have html based load balancing. We will utilize GlusterFS for the volume management. We are building our own (and yours if you follow along) ARM7 cloud. The goal being, as we move off the bare metal to the Kubernetes configurations, the configurations should be mostly transferable to the Amazon or Google clouds with little modification. We changed from trying to use Flannel which was the root of some issues (see links below) and have now moved to using Weave for the cluster networking.
We will also be setting up a Continuous Deployment environment utilizing cross platform library QEM as the basis for building out our ARM based docker containers. Gradle will be our build tool of choice.
Once the infrastructure has been built out, we will design and build a microservices based system to process sensor data. For our use case we will use utility meter data, primarily electrical, but some gas and water meter data as well. With out long experience in this space, the use case is a natural fit for our skill sets and domain knowledge. It’s also an interesting use case in that it’s one of the earliest big sensor data problems. As such, it suffers from antiquated technology stacks. Most solutions in the space start with large licensing fees and huge hardware costs before they can be implemented, so we thought we would take a modern look at an old IoT space utilizing open source and modern architectural, deployment and process principals and see where it leads us.
The Software Stack
Sensor data is really time series data, so for this project we will introduce a time series database into our stack. We are looking to use InfluxDB for this purpose. Other state data will be stored in MongoDB and perhaps relational databases depending on the type of data. For messaging and communication we will utilize Apache Kafka. Security will be managed by Keycloak. We will have posts with base deployments for each of technologies. We plan on using Micronaut for our microservices deployments. We will also build web and mobile based applications for interacting with the systems. Finally, we build in data analysis (machine learning) utilizing either Tensor Flow or Apache Spark (perhaps both).
Initial Project Parameters
The basic data managed by the system will be from the IEC CIM 61968 specification, primarily part 9 and some part 3. We will generally utilize the data object definitions from part 11. On our 6 RPi cluster we are looking to support approximately 300 electric meters providing data every 15 minutes and 20-30 water and gas meters providing data approximately 4 times a day. The system will provide validation, and extract functionality simulating billing as well as outage management and other AMI functionality. The collection of services will be the equivalent to both a head end system (HES) and a meter data management system (MDMS). We will also explore edge processing with the RPi in later projects yet to be defined.
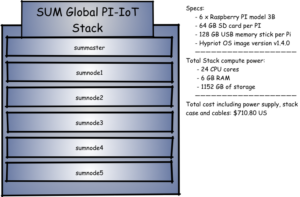
Our Hardware Stack
A picture is worth a 1000 words… its pretty simple.
The Planned Posts
Infrastructure
- Kubernetes Cluster with Raspberry Pis – Posted 5/22/2019 (UPDATED)
The Kubernetes Strikes Back– Posted 9/7/2017 (OBSOLETE)Testing our Kubernetes Cluster – Posted 4/27/2017- Deploying the Kubernetes Dashboard – Posted 5/4/2017
- RPI GlusterFS Install – Posted 5/8/2017 (revised 9/13/2017)
Docker Swarm Cluster with Raspberry Pis– Posted 7/28/2018 (Obsolete)
Software Stack
- Deploying MongoDB into our RPi DS Cluster
- Deploying InfluxDB into our RPi DS Cluster
- Deploying Apache Kafka into our RPi DS Cluster
- Deploying Micronaut “Hello RPi DS Cluster”
Building the Application
- Using Gradle with Wildfly Swarm to Build a Docker Container Microservice
- Creating a Continuous Delivery pipeline to our DS Cluster
PI-IoT Software
- Securing the Stack API with Keycloak
- Handling Utility Meter Data with Style
- Visualizing Sensor Data over Time
- Validating and Estimating Meter Data with Machine Learning – Putting the VE in VEE
- As of this posting we are still breaking this one down. Some additional proposed items are:
- Designing the “micro” in microservice data stores
- Making common services common: Exploring Person and Address
- Designing of the System with Microservices
- Posts per service and API level coordination service
- ….. more as we further define the project
We will be updating this post with links to the series and the planned posts as we move the series along. Check back soon for updates.
As always your comments and suggestions are welcome.

Social Media